
🔗 Code: https://github.com/cartesia-ai/edge
📄 Full paper: https://arxiv.org/abs/2502.14458
Authors: Aviv Bick, Tobias Katsch, Nimit Sohoni, Arjun Desai, Albert Gu
The next few years will usher in a new era of on-device AI. On-device models will power a wide range of applications—from personal assistants on your phone, to real-time translators in AR glasses, to humanoid robots that perform daily chores in your home.
This marks a major shift from today’s paradigm where models run primarily in the cloud, and where latency, privacy, and security often come at a premium.
To enable this shift, we need a dramatic increase in the efficiency of highly capable models, making them accessible across a wider range of constrained hardware environments.
Our latest technical report, “Llamba: Scaling Distilled Recurrent Models for Efficient Language Processing,” describes new ideas we’re exploring in architecture distillation—a method that transforms a pre-trained model into a new, more efficient model architecture. This enables more performant inference of a similar quality model.
There are three key reasons we’re exploring these new approaches.
- Efficiency Gains: New architectures like Mamba-2 provide a more efficient alternative to the Transformer architecture and self-attention. These architectures enable similar quality under tighter performance constraints, critical for high-throughput inference and on-device deployments.
- Deployment Flexibility: The Transformer model ecosystem is vast, with a large number of models released in the open source community every week. Bringing this ecosystem to a new set of architectures will offer users and businesses greater deployment flexibility and more choice.
- Small Model Capabilities: Small models continue to be a frontier of progress, and architecture distillation techniques enable us to advance the quality of these models. We can take advantage of the capabilities of large pretrained models and make them available in a smaller parameter count at a fraction of the cost.
Our new research shows that architecture distillation can enable us to build fast, efficient models at a fraction of the cost of pre-training.
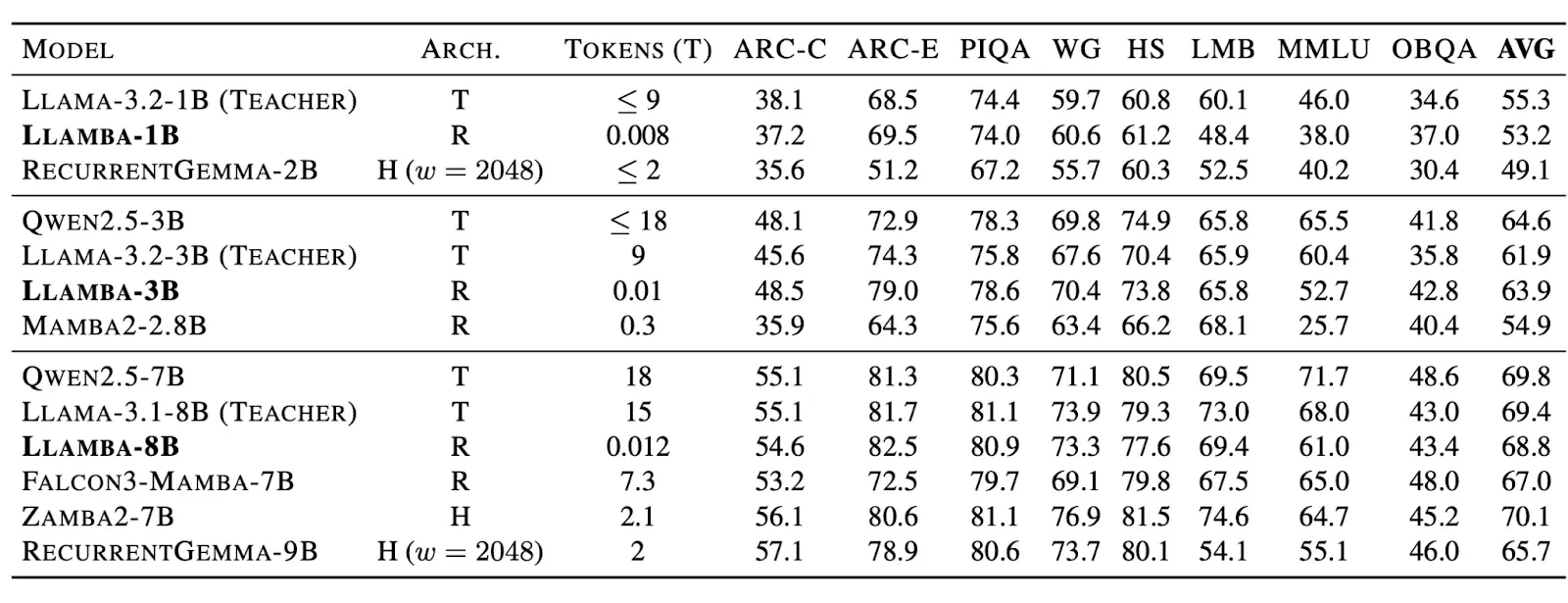
We introduce a new approach for architecture distillation called MOHAWK. This approach can be used to convert models from one architecture (e.g. Transformer) to another (e.g. Mamba-2). By applying this technique, we convert Transformer models into highly efficient Mamba-2 variants while preserving quality, and using 1000x less training data than pretraining from scratch!
Outline of MOHAWK
Our approach relies on the MOHAWK distillation framework, which aligns and transfers knowledge from a standard Transformer backbone to an efficient Mamba-2 backbone using multiple stages. This multi-stage process allows us to preserve the core competencies of the teacher model while converting its architecture into one that leverages the efficiency of Mamba-2 layers.
We make a few modifications to the original architecture, and apply this multi-stage distillation recipe.
- Alternating MLP Blocks: By interleaving Llama’s gated MLP components with Mamba-2 mixing layers, we not only maintain performance but also reduce the number of temporal mixing layers, which increases inference throughput and reduces memory usage by 2x compared to pure Mamba-2 models without MLPs.
- Multi-Head Structure Adaptation: Traditional models rely on grouped-query attention with tied embedding weights to increase speed. Instead, our Llamba models adopt an untied multi-head design. This modification is key to achieving state-size consistency, especially in long-context scenarios.
- Optimized Non-Linearities and Discretization: We remove unnecessary normalization and activation steps that could hamper alignment, and we adopt a Discrete-Mamba-2 variant that projects input matrices directly—ensuring our model matches the discrete nature of attention without extra overhead.
A Practical On-Device Implementation
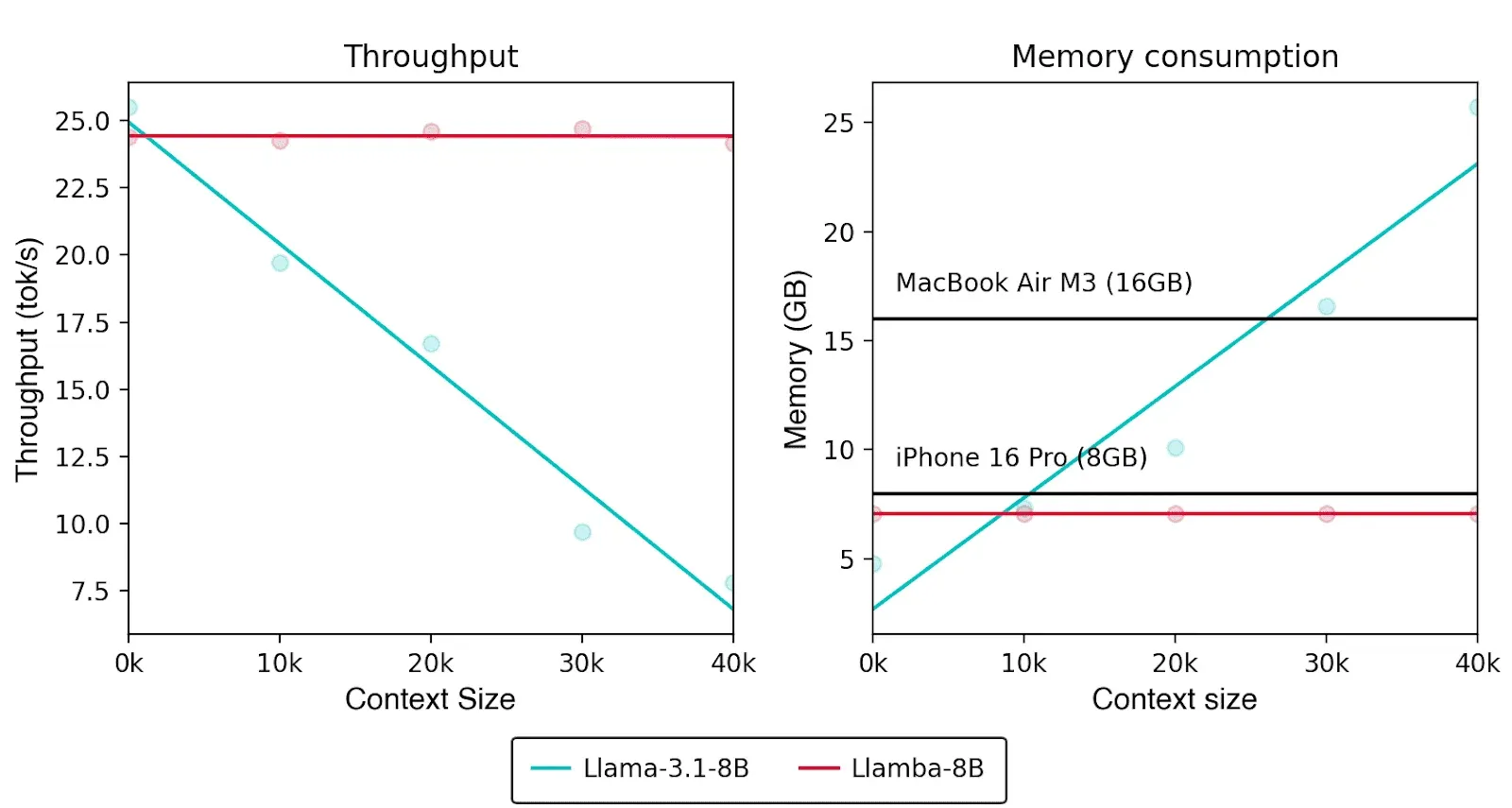
We’ve optimized Mamba-2 kernels using Apple’s Metal framework, allowing our models to take full advantage of Apple Silicon’s GPU parallelism and unified memory architecture.
Our integration with the MLX machine learning framework enables dynamic graph construction and efficient tensor operations, making it possible to run these models with consistent high throughput even in 4-bit quantization scenarios on constrained hardware.
The Llamba Family of Models
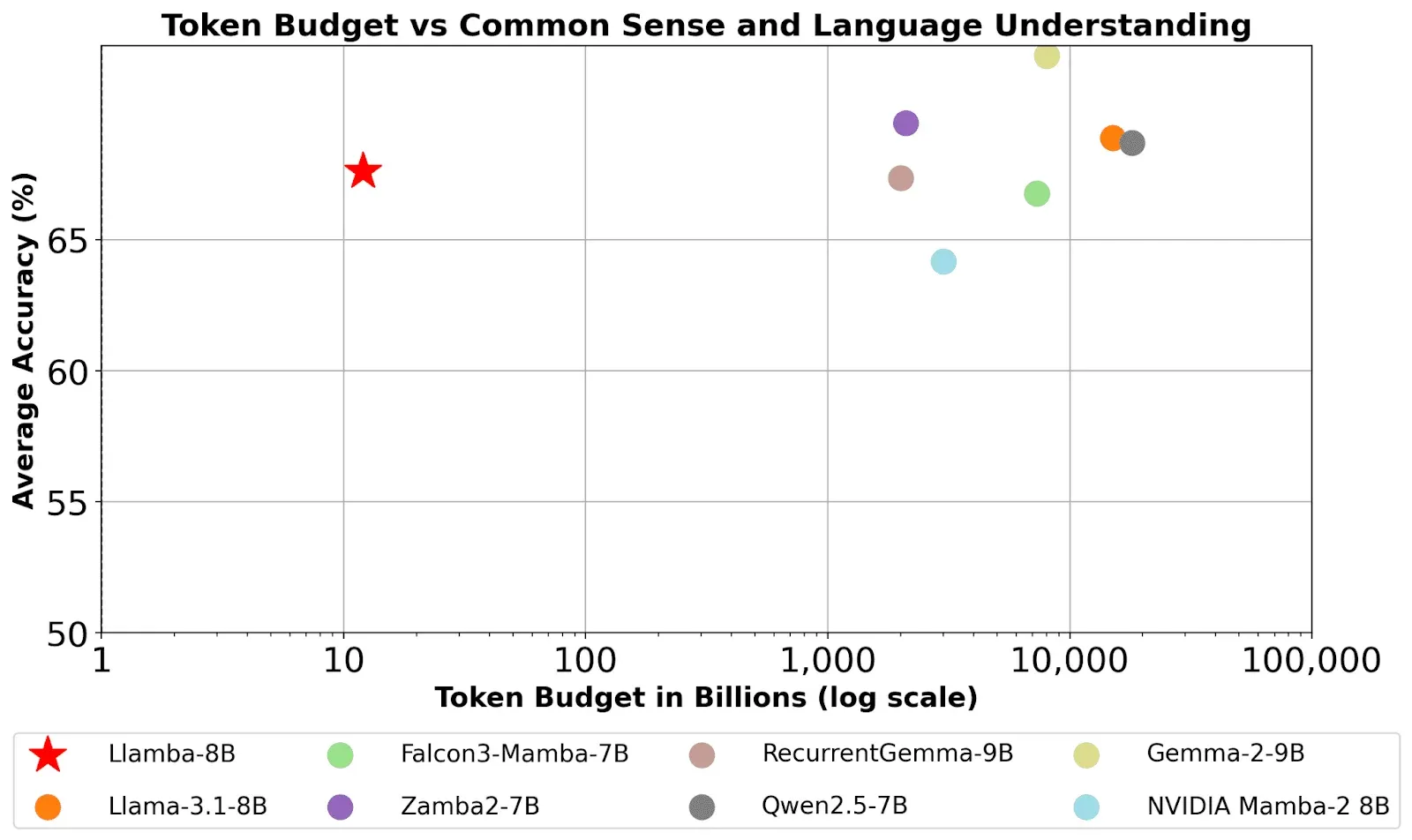
We’re making weights available for a new family of models: Llamba-1B, Llamba-3B, and Llamba-8B. These models are distilled variants of the corresponding Llama-3.X models, re-engineered to deliver state-of-the-art performance with incredible efficiency. You can try these out on Edge today.
Llamba models not only match their Transformer-based teachers on a wide range of benchmarks but also deliver remarkable throughput improvements.
For example, when evaluated on an NVIDIA H100 80GB GPU, Llamba-8B—with a generation length of 8192 tokens—processed tokens at throughputs up to 12X higher than Llama-3.1-8B. This performance gain stems from Llamba’s recurrent Mamba-2 layers, whose state size remains constant regardless of sequence length, allowing for efficient scaling even as context length increases.
By leveraging a small fraction of the data and compute typically required, our approach enables the rapid conversion of any model into an efficient variant ready for high-throughput cloud inference or real-time on-device deployment.
The future of AI is increasingly moving towards decentralization and efficiency. Our team is making advances in architecture distillation and innovating on the foundational architectures and algorithms of deep learning. We’re excited to use these technologies to create a new wave of applications—delivering smart, responsive, and accessible AI to every device.