
We’re releasing the strongest Mamba language model yet, Mamba-3B-SlimPJ, in partnership with Cartesia & Together under an Apache 2.0 license. Trained on 600B tokens, Mamba-3B-SlimPJ matches the performance of the strongest comparable 3B Transformer models with 17% fewer training FLOPs. You can read more about Mamba on arXiv and find open-source code to use Mamba on GitHub.
Get the weights on HuggingFace.
Introduction
The Mamba architecture, building on a long line of work on state-spaces models (e.g S4) and hardware-efficient algorithms (e.g. FlashAttention), has emerged as a strong contender to Transformers, but with linear scaling in sequence length and fast inference. As part of a collaboration with Cartesia and Together, we’re releasing a Mamba model with 2.8B parameters trained on 600B tokens on the SlimPajama dataset, under the Apache 2.0 license.
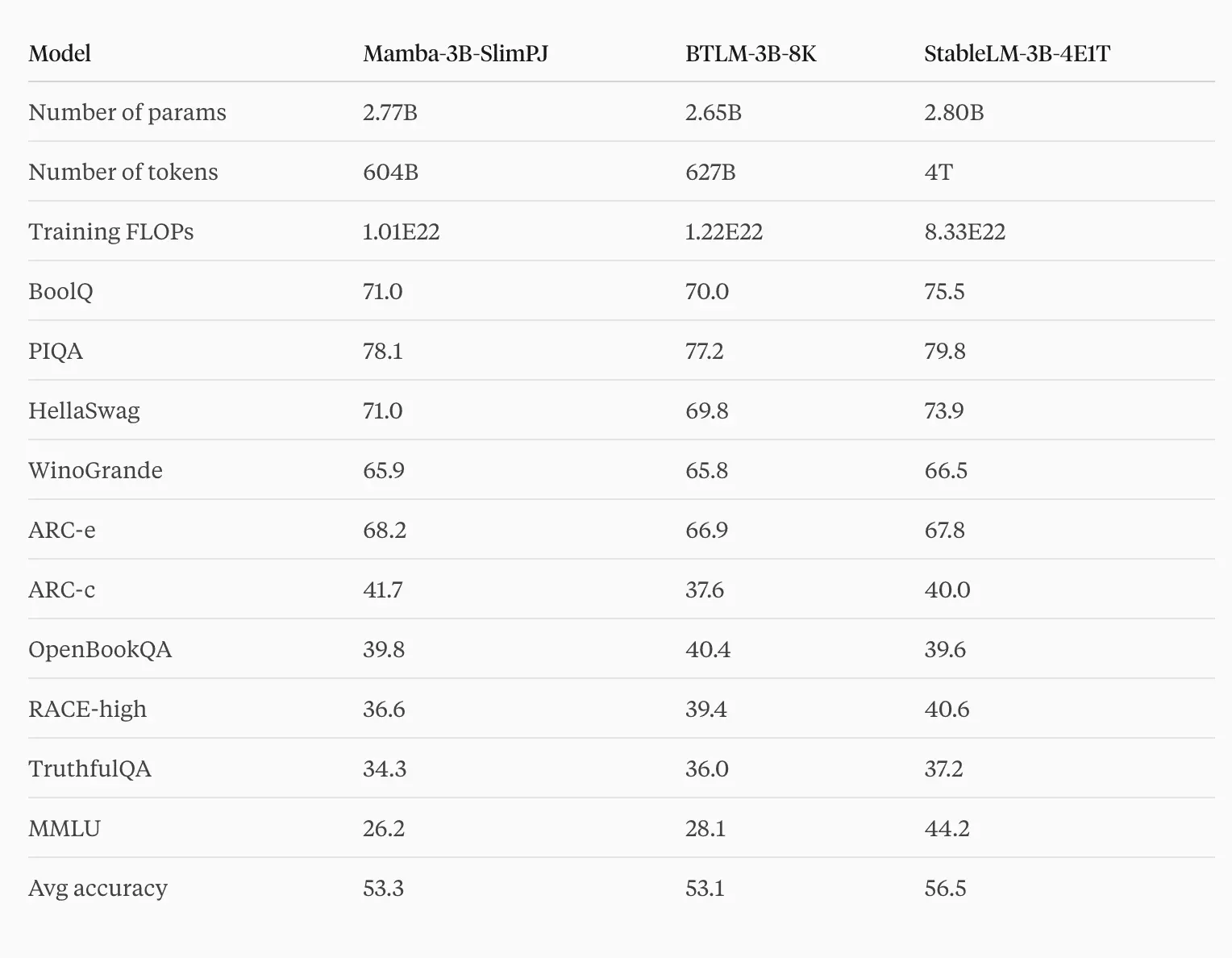
Trained on 600B tokens, Mamba-3B-SlimPJ matches the quality of some of the best 3B Transformers such as BTLM-3B-8K (also trained for 600B tokens) with 17% fewer FLOPs. BTLM-3B-8K uses a strong Transformer architecture with advanced training techniques that even surpasses some of the 7B Transformers. This further validates that Mamba is a promising architecture for building foundation models.
Training Details
We trained Mamba-3B-SlimPJ on 600B tokens, with context length 2048, using the same hyperparameters as Mamba-3B on the Pile (300B tokens), except with longer learning rate decay to accommodate more tokens. We use the SlimPajama dataset, with the GPT-NeoX tokenizer. The SlimPajama dataset is a cleaned and deduplicated version of RedPajama. This is what we love about open-source AI: different groups building on each other’s work on data and models.
Evaluation
Mamba-3B-SlimPJ matches the quality of very strong Transformers (BTLM-3B-8K), with 17% fewer training FLOPs. Generally more data and compute would yield better models, for example a similar sized StableLM-3B-4E1T trained on 7x more tokens still performs better than Mamba-3B-SlimPJ or BTLM-3B-8K.
We evaluate Mamba-3B-SlimPJ on 10 tasks (SIQA and RACE-middle, as evaluated in BTLM-3B-8K, are not yet available on lm-evaluation-harness) following the procedure in BTLM-3B-8K: BoolQ, PIQA, HellaSwag, WinoGrande, ARC easy, ARC challenge, OpenBookQA, RACE-high, TruthfulQA, and MMLU. All evaluations use zero-shot, except MMLU which uses 5 shots. We report normalized accuracies for PIQA, HellaSwag, ARC-e, ARC-c, OpenBookQA, MMLU, and accuracies for BoolQ, WinoGrande, RACE-high, and TruthfulQA (MC2 score).
Looking Ahead
Transformers such as BTLM-3B-8K can make use of more advanced techniques such as variable length training and maximal update parameterization. We look forward to exploring these techniques for Mamba training in the future.
We’ve been very happy to see the excitement around SSMs and architectures beyond Transformers in general, and Mamba in particular. Part of the motivation for this release is to provide a stronger base model for experimentation and understanding, as well as for chat and instruction-tuned models. We believe that Mamba can be a strong architecture for foundation models across modalities like language, audio and video.
About Cartesia
At Cartesia, we’re building foundation models with new capabilities on next-generation architectures like state space models, and we’re excited to have Albert leading these efforts as Chief Scientist. You can follow our work and sign up for early access here.
If you want to be part of the journey of bringing these models to the forefront of AI, come work with us! Email us at join@cartesia.ai with a resume and a paragraph with an example of your most exceptional achievement. We welcome candidates from diverse backgrounds and experiences to apply.
Acknowledgments
Thanks to Cerebras for the SlimPajama dataset, and to Cerebras and OpenTensor for the BTLM-3B-8K model. We also thank EleutherAI for the Pile dataset and lm-evaluation-harness.