
At Cartesia, our mission is to build the next generation of AI: ubiquitous, interactive intelligence that runs wherever you are. Our models and platform enable developers to build real-time, multi-modal AI systems, starting with our advances in audio and the world’s fastest generative voice API Sonic. Today, we’re announcing the first milestone in our journey to bring intelligence to every device.
We believe that artificial intelligence needs to be so incredibly efficient that it can eventually be untethered from the data center. This puts capable models on every device, and makes it possible to build applications that respect our privacy and rapidly interact with the world at volumes and speeds that seem impossible today. Applications such as agents, personal assistants, robotics, gaming, healthcare, transportation, defense, and security are just a few areas that will transform as this technology emerges.
We’ve spent the last few years pioneering a new architecture for AI called state space models (SSMs). Compared to widely used attention architectures, SSMs are highly efficient, with near-linear scaling costs in sequence length as opposed to quadratic. We believe SSMs will play a critical role in the future of AI progress and enable the creation of real-time foundation models with long-term memory and low latency that can run on every device. We’re committed to nurturing this early technology over the next few years as we progress towards our goals.
We’re now excited to bring state space models to your device. As part of this release, we’re announcing:
- Edge, an open-source (Apache 2.0) library to support the research and release of highly efficient SSMs for on-device applications across accelerators and environments. Edge brings together open-weights SSM language models, including Rene, in one place and makes them available for Apple hardware through our new SSM optimized Metal kernels.
- Rene, an open-source 1.3B parameter language model pretrained from scratch with a hybrid Mamba-2 SSM backbone, and tailored to on-device inference.
- Sonic On-Device, in private beta. Sonic On-Device is the first ultra-realistic generative voice model that supports low latency real-time streaming on device, with unlimited voices and instant voice cloning.
Collectively, these three releases represent a milestone in our goal to create radically new model architectures and platforms that break the compute requirements of today’s systems. If you’re interested in partnering with us to build the next generation of on-device AI products with Rene and Sonic On-Device, reach out to us through our outreach form.
On-Device Intelligence
The prevailing trend in AI is the creation of ever-larger foundation models, an area that will continue to grow with more investment and R&D. These large models are built for compute and energy intensive data-centers, far away from where they’re used.
What about the opposite of this? There are a huge number of use cases that will become possible as models that are “large enough” are deployed at the edge, or on-device.
This approach has differentiated advantages over the large-model-that-runs-on-cloud-via-API approach,
- Data transfer is minimized, enabling applications to continuously stream high-resolution multimodal data into the models e.g. for audio and video understanding.
- Network latency is removed, enabling application latency and reliability that would otherwise be impossible to achieve.
- Network connectivity is no longer needed, and model capabilities can be available in environments with poor connectivity, high security requirements, or with intolerance for network drops.
- Deployments are fully private and secure, never leaving the physical constraints of the hardware.
On-device AI enables new applications that can continuously process and respond to its environment in real-time. A small sample of on-device use cases we’re excited about are,
- Assistants: Turn any device into a personal assistant that proactively helps users and makes suggestions.
- Communication: Translate between languages instantly in the style of Babelfish, wherever you are.
- Security: Identify anomalies and events of interest on video cameras and take action.
- Healthcare: Privately communicate with patients in healthcare interactions.
- Education: Generate content on an iPad to safely and privately create personalized educational content for students.
- Robots: Perceive and take action with high speed and reliability in response to rapid environmental changes.
- Gaming: Generate and control video on a PC to create fully generative games.
While use cases such as those outlined above might start from prototypes that run in the cloud, the best user experience will require a shift towards edge or on-device computing.
New model architectures will be the key to unlocking faster, lower latency and more efficient deployments at the edge. We think state space models are going to be a key technology to unlock power and compute efficient foundation models that run on the edge, and we’re excited to share our first releases along this journey.
Edge: An Open-Source Library for On-Device SSMs
At Cartesia, one of our driving goals is to find new ways to bring high quality, efficient models to developers and users alike. To this end, we are open-sourcing Edge, our library for developing on-device models powered by SSMs. Edge is where we will be building out our open-source models across a suite of devices, starting with Apple’s M-series chips. Edge includes custom Metal kernels for Mamba-2 that can be reused for both laptop and mobile deployment. To facilitate local development and testing, we also released cartesia-mlx, a Python package for building on top of Edge in Apple MLX. Edge offers built-in support for optimized inference, including Metal kernel bindings, layer quantization, and more.
Availability. All official Mamba-2 models, including Rene, are now available in Edge. Stay tuned for more releases from us and the community!
Rene: An Open-Source 1.3B SSM Language Model
Rene is a small language model (SLM) designed for highly efficient on-device use. At 1.3B parameters, Rene is a hybrid SLM composed of alternating Mamba-2 and MLP layers, with some sliding-window attention (SWA) layers interspersed. Rene was trained on 1.5T tokens of the publicly available Dolma-1.7 dataset (h/t AllenAI).
Efficiency-first. With the use of Mamba-2 and SWA, Rene has a fixed memory footprint at inference time, critical for reliably running it in resource-constrained environments such as personal computing devices. The use of Mamba-2 layers enables faster prefill times compared to other pure-SSM based architectures.
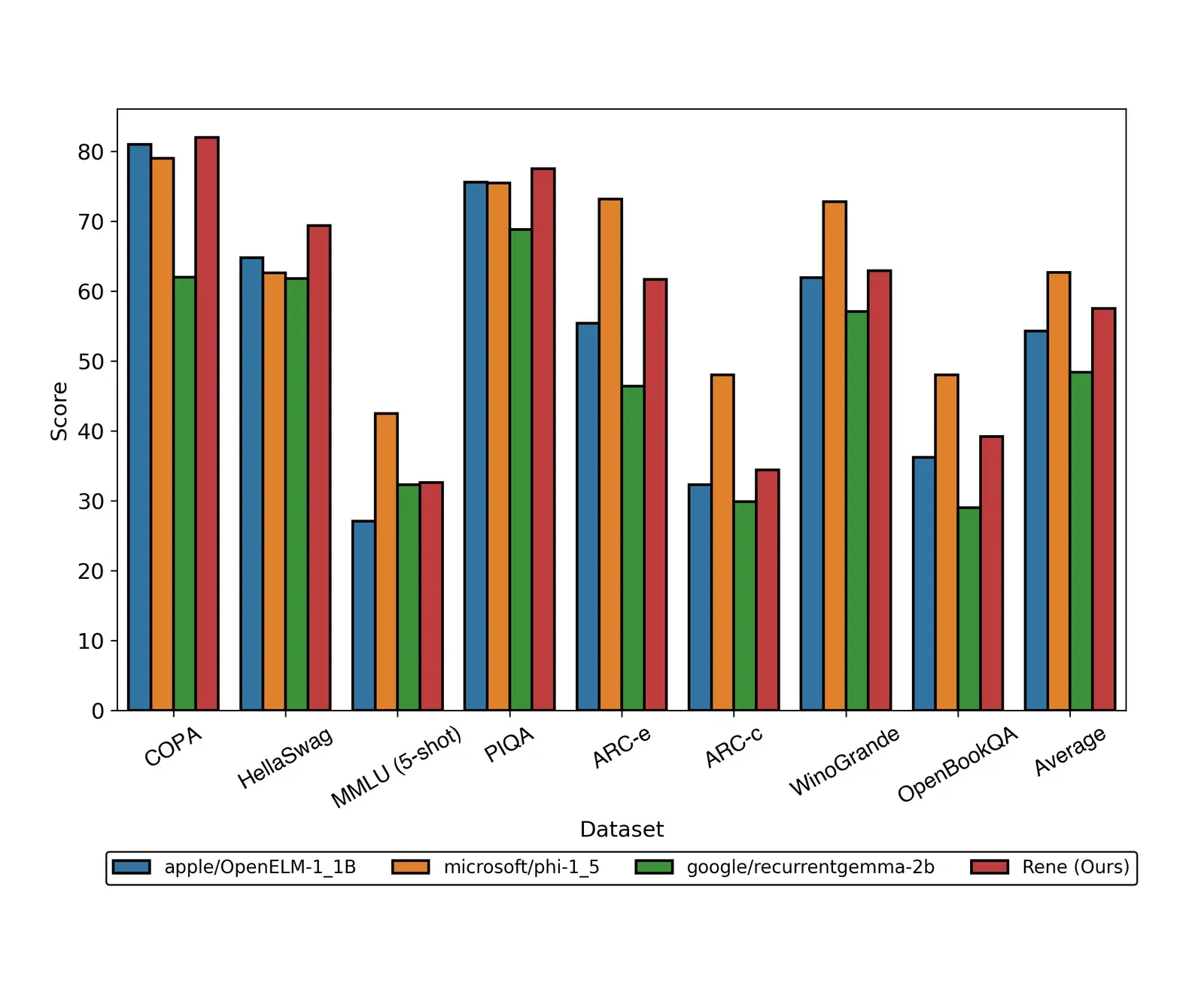
Evaluation. We compared Rene to a suite of recent open-source SLMs on a variety of standard language modeling benchmarks, using the LM Evaluation Harness. These benchmarks span several categories, including common-sense reasoning (COPA, WinoGrande, ARC-Easy, ARC-Challenge) and language understanding (PIQA, HellaSwag, OpenBookQA, MMLU). Rene also outperforms SLMs such as Apple’s OpenELM (1.1B) and Google’s recurrent Gemma (2B) (Figure 1). Rene is the first SLM based on a recurrent architecture to achieve similar performance to similarly-sized (≤2B parameters) state-of-the-art SLMs across these benchmarks.
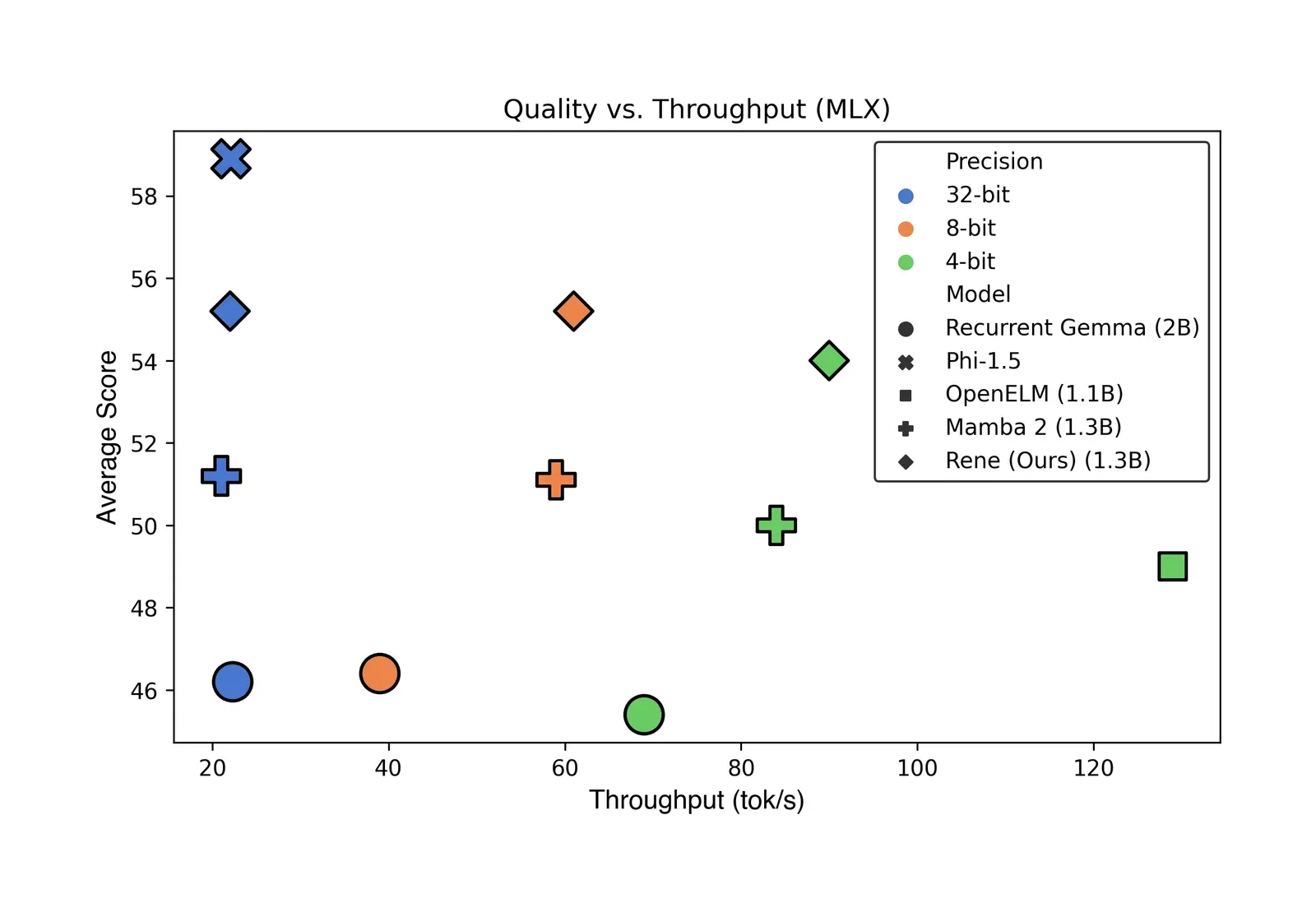
On-device. Edge supports Rene natively in MLX without any quality loss compared to its PyTorch implementation. Edge also enables 8-bit and 4-bit quantization of Rene for faster inference without any quality loss (Figure 2).
Sonic On-Device Private Beta
We’ve been amazed by the wide adoption of Sonic since its release across applications across use cases including assistants, conversational agents, gaming, education, and dubbing. Since then, we’ve gotten many requests for Sonic on device - for latency, privacy, and availability.
As part of this update, we’re announcing the release of Sonic On-Device in private beta. Sonic On-Device is the first ultra-realistic generative voice model that supports low latency real-time streaming on device. It has all the capabilities of Sonic, including support for instant cloning and controllable pronunciation, speed, and emotion. We’re excited to work with application developers and enterprises to build the next generation of on-device speech applications, including things like on-device personal assistants and real-time translation and dubbing.
Conclusion
Rene, Edge, and Sonic On-Device are the beginning of our journey towards building real-time multimodal intelligence for every device. At Cartesia, we believe a future where on-device AI is the norm requires a phase shift in how we think about model architectures and machine learning. We are excited to keep building the next generation of hardware-optimized models and platforms that will enable any user on any device to benefit from real-time, multimodal AI.
If you’re interested in partnering with us to build the next generation of on-device AI products with Rene and Sonic On-Device, reach out to us through our outreach form: