
This year at Cartesia, we’re lucky to have worked with hundreds of founders, product leaders, and engineers who are shaping the future of voice applications. In our first 2024 State of Voice report, we highlight the key infrastructure breakthroughs and emerging use cases driving the industry forward, and look ahead to what’s next in 2025.
Biggest Trends of 2024
1. New architectures for building voice interaction emerged
2024 marked a breakthrough in conversational voice AI with the emergence of orchestrated speech systems that combine STT → LLM → TTS models to listen, reason, and respond in a conversation.
Speech-to-speech technology became a reality with OpenAI’s Voice mode in ChatGPT, introducing models that are pre-trained end-to-end on audio and text information and natively understand and generate audio in addition to text tokens. While OpenAI’s implementation through their Realtime API may not be fully end-to-end yet, as evidenced by challenges with handling interruptions in their demo, it represents an important step toward using single unified models for voice interactions.
Fully duplexed speech-to-speech systems emerged as a research artifact through releases like Kyutai’s Moshi model. These models are “always on,” since unlike OpenAI’s system, they are able to listen to the user while the model is speaking. This offers an interesting glimpse into the future of multimodal voice where models are always streaming in user audio.
New model architectures for speech became viable, with Cartesia releasing Sonic TTS based on a new state space model (SSM) architecture that is trained autoregressively. These architectures represent a big departure from more traditional attention-based Transformer models that have become popular over the past few years, since they offer greater flexibility in deployment environments. Memory-efficient on-device deployments are now possible along with improved quality and latency.
2. Voice AI APIs advanced to enable natural conversations at enterprise scale
In 2024, improvements in three core components of modern voice agent architecture enabled voice AI to replace rigid “press 1 for English” phone trees with natural conversations.
- Speech-to-Text (STT): Transcription quality has become strong enough to make it a standard tool in designing audio-native applications. However, problems like domain-specific terms and far-field transcription remain challenging. In 2022, OpenAI’s Whisper laid the groundwork with its open-source model, trained on an impressive 680,000 hours of multilingual audio data. Deepgram’s Nova-2 model has since raised the bar, achieving a 30% reduction in Word Error Rate (WER) and setting new benchmarks for commercial applications in 2024.
- Large-Language-Model (LLM): The release of GPT-4o, Llama 3.2, Claude 3.5 Sonnet, and Gemini 2.0 in 2024 marked substantial improvements in reasoning and efficiency. LLM costs dropped dramatically from $45/million for GPT-4 to $2.75/million tokens for Llama 3.1 70B running on Together AI. Speech models now support input streaming, allowing audio to generate in real-time as they receive inputs from an LLM while maintaining consistent prosody across speech segments.
- Text-to-Speech (TTS): TTS models have reached production-grade maturity, delivering reduced latency, enhanced naturalness, and improved accuracy in handling complex content such as acronyms and numerical expressions. Leading TTS engines have transformed synthetic voices from their robotic origins to truly human-like speech. This progress is driven by innovations in neural network architectures (SSMs, transformers, diffusion models), advancements in training data quality and diversity, and the optimization of audio codecs—essential for efficiently encoding and decoding digital audio for streaming or storage.
Voice AI providers also evolved beyond their initial focus on prosumers and voice-native startups to meet enterprise demands. Voice AI systems had to be fundamentally redesigned to meet rigorous standards for real-time interactions that exceed those of traditional asynchronous applications. Since live conversations can’t be edited or regenerated, the infrastructure must deliver guaranteed uptime, flawless concurrent call handling, and uncompromising reliability. To serve traditional enterprises, providers upgraded their platforms to offer customizable SLAs, dynamic scaling for peak volumes, robust security certifications, and self-hosted options for highly regulated industries. These features were rare in early voice AI offerings but have become standard as the technology matured.
3. New platforms made it easier than ever to build, test, and deploy custom voice agents in production.
Most voice agents today are built on a core conversational pipeline–Speech-to-Text (STT), Large Language Model (LLM) reasoning, and Text-to-Speech (TTS).
While this pipeline creates natural conversations, building it in-house presents significant challenges: managing real-time audio streams, handling model latencies, coordinating turn-taking, and ensuring seamless transitions. What typically takes engineering teams 6-12 months to build can be implemented in weeks using speech orchestration platforms. These platforms abstract away the complexities and allow developers to focus on crafting engaging experiences while mixing and matching best-in-class components.
Companies like LiveKit and Daily developed open-source components for seamless, latency-optimized orchestration across real-time AI models using a WebRTC stack. Their infrastructure ensures reliable performance globally while allowing developers to maintain full stack customization.
Voice agent orchestration platforms such as Vapi, Retell, Bland, and Thoughtly, emerged to enable rapid deployment of custom agents, complete with advanced features like RAG-powered knowledge bases and tool calling functionality. These platforms offer additional capabilities like Voice Activity Detection (VAD) to control speaker switching and emotion recognition, interruption handling, and noise filtering models to facilitate natural conversation.
New observability platforms like Hamming, Coval, Vocera, and Canonical built entire evaluation suites for simulating and measuring voice agent quality at scale.
4. Voice agents emerged across every vertical
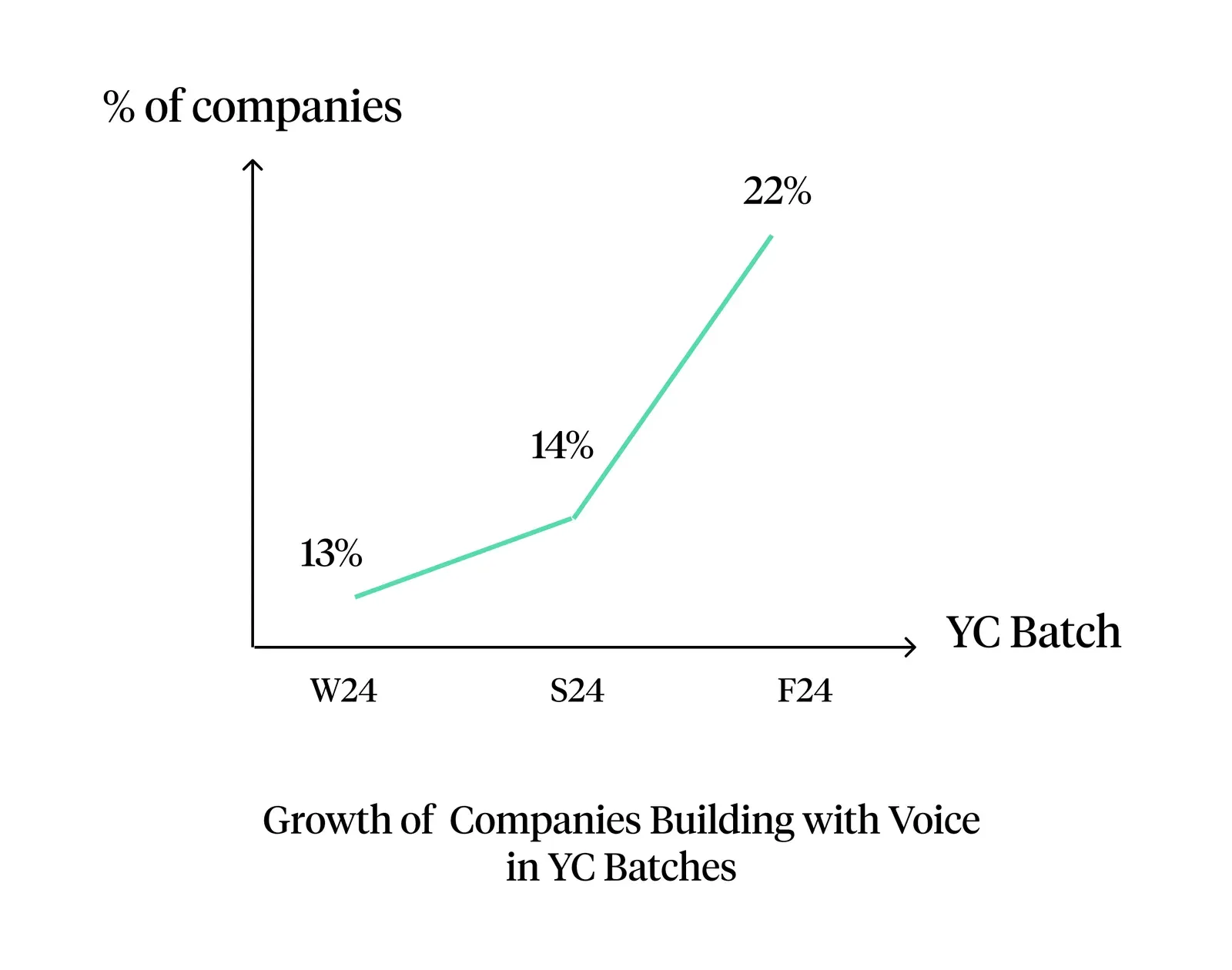
Vertical voice agent startups saw explosive growth, with Y Combinator reflecting this trend as the number of voice-native companies grew by 70% between the Winter and Fall cohorts. Initial adoption focused on expanding capacity for previously understaffed services like 24/7 customer operations and seasonal volume surges.
- Loan Servicing: Salient and Kastle’s agents help service loans, manage payoffs, and handle outreach for reactivating dormant accounts or cross-selling other financial products—all while maintaining high compliance standards for handling sensitive data like PII.
- Insurance: Liberate and Skit’s agents handle 24/7 claims processing, policy renewals, and provide clear explanations of coverage options.
- Healthcare: Abridge first brought transcription to healthcare in response to the high demand for medical scribes in 2019. Now, clinics worldwide are adopting AI assistants for scheduling appointments, providing medication reminders, and answering billing queries thanks to companies like Hello Patient, Hippocratic, Assort Health, and Superdial—all while safeguarding patient information.
- Logistics: Freight brokers, third-party logistics providers (3PLs), and carriers utilize Happy Robot and Fleetworks to manage check calls, load updates, payment statuses, and appointment scheduling.
- Hospitality: Use cases range from Host AI’s omnichannel AI assistant for hotels to Nowadays’ AI event planner. Elise AI’s AI assistant and CRM working hand in hand to handle everything from leasing inquiries to maintenance and renewals.
- SMBs: Goodcall allows smaller franchises to easily set up AI agents to handle all their inbound calls seamlessly, as owners currently miss 60% of phone calls due to capacity constraints. Slang has purpose-built solutions for restaurants and Numa has integrated with car dealership CRMs to leverage past customer interaction data to drive retention. Avoca powers 24/7 AI call centers for HVAC, plumbing, and other field services.
5. Voice Agents streamlined core business functions
Voice agents also emerged for standardized business processes, with significant adoption across three key areas:
- Recruiting: AI interviewers like Mercor and Micro1 enhance the hiring process by conducting phone and video interviews, using candidates’ backgrounds to craft relevant questions and provide deeper insights than traditional application screening.
- Sales: As email effectiveness declines, companies like 11x, Artisan, and Nooks are revitalizing phone-based sales with AI SDRs for prospecting and lead qualification. Meanwhile, platforms like Hyperbound simulate sales scenarios to improve rep performance through AI-powered role-play training.
- Customer Support: AI-driven customer experience platforms like Sierra, Decagon, Forethought, Parloa, and Poly are incorporating voice capabilities to support the large volume of customer support interactions that still occur over the phone.
6. Voice AI powered more engaging entertainment and media experiences with interactive characters
- Content Creation: AI avatar platforms like Heygen, Tavus, D-ID, Synthesia, and Hedra enable creators to generate unlimited narrated videos from a single digital clone, transforming production of marketing, training, and educational content. Creator platforms like Capcut, Canva, Adobe, and Captions now integrate AI voices directly, while major outlets like Time and The New York Times are adopting AI narration for articles, democratizing professional-quality content creation.
- Gaming: Gaming studios are leveraging Voice AI to create more immersive experiences through dynamic, responsive NPCs that adapt to player interactions in real-time. Platforms like Ego and Inworld enable the creation of rich 3D worlds where AI characters engage naturally with players, while real-time voice changers allow players to match their voice to their in-game characters, enhancing the immersive experience.
- Consumer Services: Voice AI is enabling creators and service providers to scale their personal impact exponentially. Influencers and celebrities can engage with thousands of fans simultaneously through Delphi, while coaches and therapists can provide 24/7 personalized guidance through platforms like Sonia. Educational platforms like Duolingo and Khan Academy extend their reach through AI-voiced tutors, while Google’s NotebookLM lets anyone create audio summaries of articles and books. Companies like Replika and Character AI offer always-available companions for any demographic, while specialized platforms like Tolvia serve the senior population. Finally, Quora’s Poe and Perplexity’s voice to voice feature allow widespread access to LLM content via voice.

What to Expect in 2025
1. Speech to Speech models go mainstream
Speech-to-Speech (S2S) models convert speech input directly into speech output, bypassing the need for text representation. While several S2S models emerged in 2024, we expect 2025 to be their breakthrough year as they demonstrate compelling capabilities across three key dimensions that traditionally challenge STT→LLM→TTS pipelines:
- Latency: Current voice agents achieve best-in-class latency of ~510 ms (Deepgram STT: 100ms, GPT-4: 320ms, Cartesia TTS: 90ms), still far from human conversation’s ~230ms. Early S2S models like Moshi, released this year, demonstrate potential for 160ms latency through single-step processing, though they need better mechanisms to avoid generating responses before users finish speaking.
- Contextual Awareness: S2S systems allow the same model to process, understand, and generate speech directly. By processing everything in a single model, S2S models preserve non-linguistic elements like emotion, tone, and prosody that are typically lost in text conversion. While current systems try to pass this information as metadata between components, unified S2S processing will better capture conversational nuances. The main barrier remains computational cost, but once solved, both performance and efficiency will improve.
- Interruption Handling: Rather than enforcing strict turn-taking, S2S models can process overlapping speech streams in parallel. However, current systems struggle with self-speech recognition, limited context windows, and overlapped audio processing. We expect significant improvements in these areas throughout 2025.
2. Voice agents will be trusted with more complex, multi-step tasks and become more deeply engrained into workflows across all verticals
2024 marked an initial testing phase for voice agents, primarily handling overflow and basic screening tasks with predictable conversation turns. As blind A/B tests demonstrated superior performance metrics - from call durations, resolution rates, revenue recovery rates, and customer satisfaction scores (CSAT), businesses gained confidence in AI-powered voice interactions. Voice AI is poised to become the primary interface for how consumers engage with businesses on a daily basis, from booking restaurant reservations and scheduling medical appointments to paying bills and handling DMV services.
For example, imagine calling an airline to rebook and having an AI agent handle your needs end-to-end using Retrieval Augmented Generation (RAG) to instantly access passenger records, flight availability, and airline policies. This eliminates the need for hold times or department transfers - the AI can simultaneously verify current bookings, identify alternatives, apply relevant policies, and process changes while maintaining a natural conversation. Similar to how you might fine-tune an LLM on your knowledge base, enterprises may want to fine-tune existing transcription and TTS models on their domain or company-specific dictionary and style to further solidify trust in their AI agents. This growing confidence in AI’s ability to resolve complex tasks end-to-end is reflected in new agent pricing models, with vendors now offering outcome-based pricing tied to successful task resolution rates rather than call duration.
3. Compact, on-device models will enable local conversations anywhere
Compact, on-device AI models are gaining traction by solving three critical challenges: they run without internet connectivity, deliver lower latency by processing locally, and ensure privacy by keeping data on the device. This enables voice AI in scenarios where these requirements are non-negotiable—from vehicles operating in remote areas to field workers in signal-dead zones.
We expect 2025 to be the breakout year for on-device voice AI as new architectures, model quantization and distillation techniques mature and specialized edge AI chips become widely available, finally making local processing practical at production scale. Advances in frameworks like TensorFlow Lite and PyTorch Edge are accelerating this shift already by making deployment and optimization more accessible.
4. Fine-grained control advances across every aspect of voice
2024 brought significant advances in controlling nuanced aspects of synthetic speech, from emotional tone and pacing to precise pronunciation. These capabilities are expanding beyond voice alone, enabling seamless coordination between speech characteristics and other AI modalities - for example, emotional cues in voice can now drive matching expressions in digital avatars’ body language through Speech Synthesis Markup Language (SSML), which is currently responsible for dictating pauses or spelling. Creators will be able to seamlessly insert AI-generated words or scenes into existing audio, with the new content automatically adopting the style and timing of the surrounding material.
Looking Ahead
2025 will see voice AI become more powerful, customizable, and accessible across industries as the technology matures from early experiments to production-ready systems.