
How to Build a Voice AI Agent with Cartesia
Tired of robotic conversations with Siri and Alexa that end with “Sorry, I don’t understand”? The future of voice AI is here. These new AI agents can engage in natural conversations, understand context, and respond with human-like intelligence.
Unlike traditional voice assistants that merely execute basic commands, these AI agents transform customer experiences. Instead of navigating tedious “Press 1 for English” phone menus, you can simply tell the AI what you need—just like talking to a human.
Let’s explore how to build these powerful voice AI agents using the Cartesia API.
What are voice AI agents?
Voice AI agents are intelligent systems that engage in natural conversations with humans. They can understand and respond to spoken language—from answering simple questions to handling complex tasks. These agents combine speech recognition, natural language processing, and text-to-speech technology to create seamless voice interactions.
Voice AI agents can handle many routine tasks, such as:
- Answering frequently asked questions
- Scheduling appointments
- Check status of an order
- Routing calls to the correct department
- Providing basic troubleshooting support
By delegating these routine interactions to AI, teams can concentrate on more complex and meaningful work, making better use of their time and resources.
How voice AI agents work?
Voice AI agents use artificial intelligence to process human speech, interpret its intent, retrieve information from company knowledge bases, synthesize appropriate text responses, and deliver them in a natural, conversational voice.
The workflow is as follows.
- Speech-to-Text (ASR) - The user speaks, and the AI system transcribes their voice into text through speech recognition.
- Natural Language Processing - The system analyzes the text to understand the user’s meaning and intent, including context and nuances.
- Information Retrieval - Using the understood intent, the AI agent pulls relevant information from its knowledge base to craft a response.
- Response Generation - The AI generates appropriate responses based on the conversation context and retrieved information.
- Text-to-Speech - The AI agent converts the response text into natural speech for the user. Delivering a conversational and natural experience.
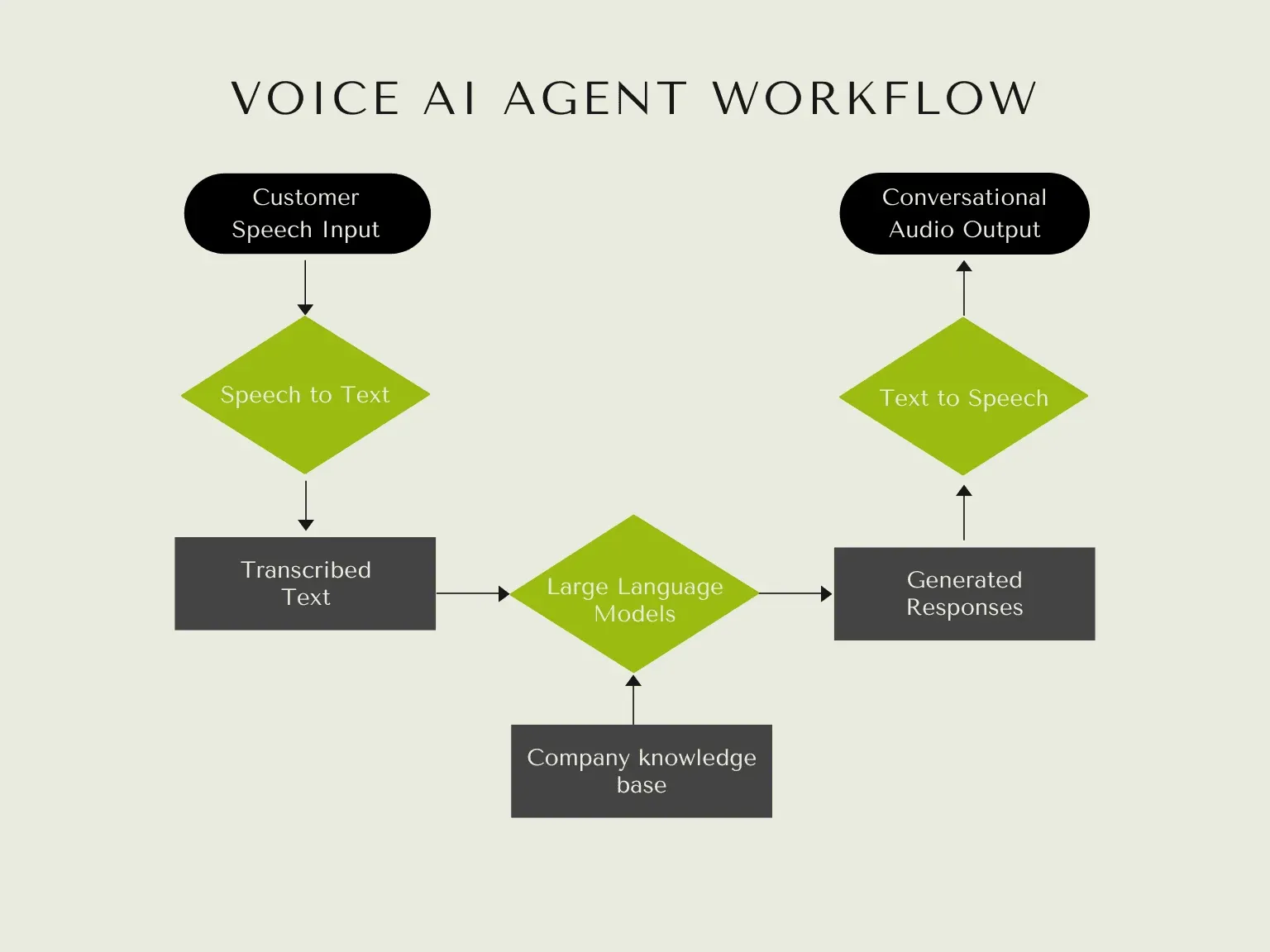
Voice AI Agent workflow
The AI agent can start the conversation following a pre-recorded script. For example, it may say something like “My name is _____. How can I assist you today?”
Your system can then record user responses, convert speech to text, and pass the text input to your LLM or internal AI system in real-time. The LLM can generate a suitable text response that can be passed back to the voice AI agent to convert to speech. The conversation can flow fluently between the voice AI agent and the end user until your system reaches its goal — e.g., confirming an appointment or troubleshooting a common issue.
Building a voice AI Agent with Cartesia API in Python
This tutorial walks you through setting up a voice AI agent using the Cartesia API and the Sonic model.
Set up the environment
To use Cartesia’s API, you need an account, an API key, and FFmpeg installed. Follow these steps:
- Create a Cartesia account at Cartesia Play.
- Get your API key from Cartesia API Keys.
- Install FFmpeg for audio processing as shown
# On Ubuntu/Debian
sudo apt update && sudo apt install ffmpeg
# On macOS (using Homebrew)
brew install ffmpeg
# On Windows (using Chocolatey)
choco install ffmpegFFmpeg isn’t required to use the Cartesia API, but it’s helpful in converting, saving, and playing audio files.
Choose your speech-to-text endpoint
As a first step, you’ll need to record customer input and convert it to text. There are several speech-to-text technology options. For example, you can use Whisper API, developed by OpenAI, which supports various audio formats and can transcribe speech in multiple languages. Additionally, it can translate non-English speech into English. Alternatively, you can use services like Google Speech to Text, Amazon Transcribe, Azure AI Speech, Assembly, Deepgram or Speechmatics.
Generate a response from the transcribed text
Generating a response depends on your core AI app functionality. For example, if your voice AI agent works in healthcare, you must communicate with your existing medical AI apps and healthcare databases. If you plan to use it for appointment scheduling, you will need to look up data in your calendar apps. Building out this functionality typically involves using another AI model with more reasoning capabilities. Anthropic Claude Sonnet, or OpenAI O1 or 4O models.
Use an voice AI agent platform instead
If all these start to sound too complicated to set up, you can also try platforms like LiveKit, VAPI, or RASA to kick start building voice AI agents.
The simplest proof of concept voice agent is just fifty lines of code (not counting whitespace or comments):
load_dotenv(dotenv_path=".env.local")
logger = logging.getLogger("voice-agent")
def prewarm(proc: JobProcess):
proc.userdata["vad"] = silero.VAD.load()
async def entrypoint(ctx: JobContext):
initial_chat_context = llm.ChatContext().append(
role="system",
text=(
"You are a voice assistant created by LiveKit. Your interface with users will be voice. "
"You should use short and concise responses, and avoid usage of unpronounceable punctuation. "
),
)
logger.info(f"connecting to room {ctx.room.name}")
await ctx.connect(auto_subscribe=AutoSubscribe.AUDIO_ONLY)
# Wait for the first participant to connect
participant = await ctx.wait_for_participant()
logger.info(f"starting voice assistant for participant {participant.identity}")
# Set up the Agent
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
stt=deepgram.STT(),
llm=openai.LLM(model="gpt-4o-mini"),
tts=cartesia.TTS(
model="sonic-3.5",
voice="a0e99841-438c-4a64-b679-ae501e7d6091",
),
chat_ctx=initial_chat_context,
)
agent.start(ctx.room, participant)
# Once connected, we start by hardcoding a greeting
await agent.say(f"Hey {participant.identity}! How can I help you today?", allow_interruptions=True)
if __name__ == "__main__":
cli.run_app(
WorkerOptions(
entrypoint_fnc=entrypoint,
prewarm_fnc=prewarm,
),
)Format text input
Properly formatted input text is essential for achieving natural-sounding speech output. Best practices include:
- Use punctuation to indicate inquiry and emphasis, ensuring the speech sounds natural.
- Expand abbreviations to avoid mispronunciations (e.g., writing “Doctor” instead of “Dr.”).
- Structure text in a way that matches natural speech cadence.
You can also use
Example script
Hello! Thank you for calling our customer service.
<break time="1s" />
I’m Anna, how can I help you today?
<break time="1s" />
Could you please provide your order number so we can get started? We’ll resolve this as quickly as possible and keep you updated.
<break time="1s" />Choose your text-to-speech endpoint
Cartesia provides multiple TTS endpoints. Websocket and stream endpoints are suitable for interactive voice agents for the following reasons:
- Latency: You can establish a WebSocket connection in advance, which means that you do not incur any connection latency when you start generating speech. (This usually saves you about 200ms.)
- Input Streaming: You can stream in inputs while maintaining the prosody of the generated speech, which is useful when generating text inputs in real-time, such as with an LLM.
- Timestamps: You can get timestamped transcripts for the generated speech to build features like subtitles or live transcripts. Model and language limits apply — see Compare TTS endpoints.
- Multiplexing: You can multiplex multiple conversations over a single connection.
TTS bytes(Post) endpoint is ideal for generating an audio output file in advance. You can use it to create audio outputs in various formats, such as WAV and MP3.
Before selecting an endpoint, review the API documentation at Cartesia TTS Endpoints to determine which one best suits your application.
Call the API
Once the text is formatted correctly, it can be sent to the TTS endpoint chosen previously. The API expects a JSON payload containing the text and optional configuration parameters. You can set it up as shown with the Cartesia SDK for Python.
pip install cartesia
# Or using uv
uv add cartesia
# Make the API call
import os
import subprocess
from cartesia import Cartesia
if os.environ.get("CARTESIA_API_KEY") is None:
raise ValueError("CARTESIA_API_KEY is not set")
client = Cartesia(api_key=os.environ.get("CARTESIA_API_KEY"))
response = client.tts.generate(
model_id="sonic-3.5",
transcript="Hello, world! I'm generating audio on Cartesia.",
voice={"mode": "id", "id": "a0e99841-438c-4a64-b679-ae501e7d6091"}, # Greg - Supporter
language="en",
# You can find the supported output_format at https://docs.cartesia.ai/api-reference/tts/bytes
output_format={
"container": "wav",
"encoding": "pcm_f32le",
"sample_rate": 44100,
},
)
with open("sonic.wav", "wb") as f:
f.write(response.read())
# Play the file
subprocess.run(["ffplay", "-autoexit", "-nodisp", "sonic.wav"])Run the script as shown below
env CARTESIA_API_KEY=YOUR_API_KEY python cartesia.py
# On uv
env CARTESIA_API_KEY=YOUR_API_KEY uv run cartesia.pyThis script sends the text input to the Sonic model, retrieves the audio output, and saves it as a .wav file.
Configuring your voice agent
Cartesia’s API allows users to customize the voice output further, such as adjusting speed, emotion, and localization.
Speed
Add the speed parameter in the __experimental_controls dictionary to the voice object in your API request to customize speed.
Speed options are:
- “slowest”: Very slow speech
- “slow”: Slower than normal speech
- “normal”: Default speech rate
- “fast”: Faster than normal speech
- “fastest”: Very fast speech
You can also define speed as a number within the range [−1.0,1.0] for more granular control. A value of 0 represents the default speed, while negative values slow it down and positive values speed it up.
"voice": {
"mode": "id",
"id": "VOICE_ID",
"__experimental_controls": {
"speed": "fast,
}
}Emotion
Add the emotion parameter in the __experimental_controls dictionary to the voice object in your API request to customize emotion. The emotion parameter is an array of “tags” in the form emotion_name: level.
Emotion names can be anger, positivity, surprise, sadness, curiosity.
Emotion levels are lowest, low, high, and highest. They are purely additive. For example, “surprise: low” will add a small amount of surprise to the voice, not make it less surprised. Omit the level for a moderate addition of the emotion.
"voice": {
"mode": "id",
"id": "VOICE_ID",
"__experimental_controls": {
"emotion": [
"positivity:high",
]
}
}Stream Inputs
For interactive applications, you may want to generate speech dynamically from an AI model, such as a large language model (LLM). Cartesia’s API supports real-time voice generation through a feature we call continuations. They continue the generation from where the last one left off, maintaining the previous generation’s sound pattern and context.
Continuation is configured using context_id in your text input. All words/phrases in a continuous sentence should be marked with the same context_id.
{"transcript":
"Hello, Sonic!",
"continue": true,
"context_id": "stream1"
}
{"transcript":
" I'm streaming ",
"continue": true,
"context_id": "stream1"
}
{"transcript":
"inputs.",
"continue": false,
"context_id": "stream1"
}You can send the generation request with the context_id to the TTS WebSocket endpoint. Further inputs with the same context_id will continue the generation, maintaining prosody.
This feature is handy for voice ai agents, chatbots, and interactive experiences.
FAQs about voice AI agents
Is voice AI technology usable yet?
Yes, businesses are actively adopting voice AI solutions. Platforms like Cartesia enable high-quality voice generation, low latency, and realistic conversational voices. AI voice agents can answer questions based on an information database and handle tasks like scheduling appointments, creating CRM records, making outbound calls, and qualifying leads.
What types of businesses can benefit from voice AI agents
Industries such as healthcare, call center, gaming, medical insurance, and more are already using AI voice agents. Any business with a high volume of calls each month can benefit from this technology by automating customer interactions and improving operating efficiency.
Can AI voice agents speak languages other than English?
Yes, voice AI agents can support multiple languages, but the quality depends on the text-to-speech (TTS) provider. For instance, Cartesia supports 15 languages, including Spanish, German, French, Italian, and Hindi.
How customizable are AI voice agents?
Voice AI agents can be tailored to meet your specific business needs. They can be trained using your company’s data to accurately respond to customer inquiries, and their voices can be customized to align with your preferences. Additionally, these agents can integrate with your existing systems, such as websites, CRM platforms, calendars, and any software with API endpoints, ensuring a smooth transition into your current workflows.
Do AI voice agents still sound robotic?
No, modern AI voice technology has significantly reduced robotic-sounding speech. Speech generation now better handles natural pauses, interruptions, and conversational nuances. The difference between AI-generated and human speech is becoming increasingly hard to detect, especially when using high-quality TTS providers like Cartesia.